Building Small Language Models Using Knowledge Distillation (KD)
Techniques & practices in distilling knowledge for language models
Recent trends in large language models show promising results in both language modeling and generation tasks. Noticeably, the results are proportional to the size of the model — number of parameters, size of training data, and GPU hours. The output of these models can be customized using the two most common approaches — RAG and fine-tuning using custom datasets. In this blog, we will understand few common flaws in RAG, challenges in fine-tuning language models. This blog provides an overview of the fundamental concepts of Knowledge Distillation (KD) and includes a practical example to illustrate its application.
RAG, stands for retrieval augmented generation. In RAG, the application logic is responsible for retrieving the content that is semantically related to user’s query. The content along with prompt is sent to the language model. In short, this approach depends on retrieval strategy, quality of input data and prompts. It also relies on one-shot capabilities of the language model, hence larger language models that can accept more input generate better responses. However, unless done correctly this solution is prone to biased responses, repetitions and hallucinations. As the text corpus grows, it becomes difficult to identify the semantically correct input for user’s query.
The alternative for customizing the response from a language model is task specific fine-tuning. In this approach the models are fine-tuned using labelled datasets. Task specific fine tuning improves the quality of response and overcome the limitations of one-shot learning. In fine-tuning for a specific task, the model is trained for several iterations, using different hyper parameters and large labelled datasets. During this process, snapshots of the best model, activations, and gradients are stored in GPU memory. The default approaches to fine-tuning has the following issues:
Cost of fine tuning: Task specific fine tuning needs several cores of GPU for hundreds of hours (depending on size of data) and GBs of RAM. Production systems should quickly adapt to the changes in data, this makes fine-tuning a continuous activity. Data scientists may also want to experiment with different configurations of the model, this makes the iterative approach more expensive. Fine-tuning a model with 5K tokens is roughly estimated as 6 hours (source). The below table shows the cost for 500 hours of training (or 450K tokens) using different models on Azure Open AI.

Deployment in resource constrained environments: During inference these models require high memory for better performance. The number of parameters in the model determines the size of memory required. For example, a 7 billion parameter model requires over 14GB of memory. This is just to load the parameters in half-precision floating point format. Expectedly, it exceeds the capabilities of most edge devices. There are several approaches for compressing the model sizes without much comprise in quality, like PEFT methods — LoRA, QLoRA, Quantization, Knowledge distillation. This blog mainly focuses on knowledge distillation in large language models.
If you are already aware of the concepts and want to see the code you may go to my notebook from here. In this notebook, I distilled knowledge from fine-tuned T5-small teacher model to smaller T5-small model using forward KL-divergence. The models size reduction without compromising on performance is noticeable in below table. The size of the model can be further reduced with more hours of training.

Nevertheless, if you want to understand the fundamentals of knowledge distillation, read on.
What is knowledge distillation?
Knowledge distillation is a technique that aims to compress a large and complex model (the teacher model) into a smaller and simpler model (the student model) while preserving the performance of the teacher to some extent. Knowledge distillation is not a new approach, it was proposed by Critstian Bucilua et al. in this paper in year 2006. Formerly, KD was applied to any neural network model with effectively large architectures.
Knowledge distillation from teacher models can be done using the responses (or logits) of the teacher (also called as response-based knowledge distillation), weights and activations of the teacher model (also called as feature-based knowledge) and relationships between the model parameters (also called relationship-based knowledge). This blog focuses on using response-based knowledge in large language models. The below image shows knowledge distillation using response-based knowledge from larger teacher model.
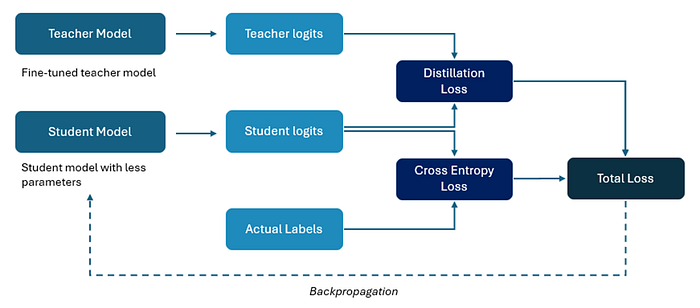
Response-based knowledge in Large Language models.
In response-based knowledge distillation the idea is to use the teacher’s outputs as soft labels for the student. The student is trained to predict teacher’s softlabels instead of actual labels. This way, the student can learn from the teacher’s knowledge without having to access the teacher’s parameters or architecture. Using this approach knowledge distillation can be applied in two ways — white box KD and black box KD.
Black box KD: In black box KD, only the teacher model’s prompt and response pairs are available. This approach is applicable to models that do not predict logits.
White box KD: In white box KD, teacher model’s log probabilities are used. White Box KD is applicable only to open-source models that produce logits.
How effectively we can use logits to distill the knowledge is an active area of research. In the notebook attached, we see a very basic form of KD.
Loss function.
Why do we think this approach would work? The easiest way to understand this question is to learn the loss function. The loss function contains 3 key components — teacher’s logits, student’s logits and temperature.
Teacher model’s logits represent the purest form of predictions before applying any non-linear activation function. Similarly, student models also produce logits. Logits of any two classes cannot be compared, hence we normalize the logits. We apply non-linear activation functions like softmax to normalize the logits. The normalized logits represent a probability distribution over N classes, also called as soft labels. Our goal is to reduce the difference between the probability distribution of teacher model and student model, this way student model behaves more like teacher model.
Kullback-Leibler divergence loss (or KL divergence loss) is one approach to compute the difference between any two probability distributions. In KD we use KL divergence loss to improve the learnings of student model using teacher model distributions. The following equation describes KD Loss.
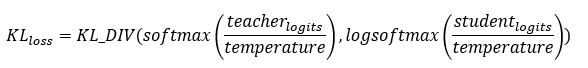
In the above equation, temperature is a hyperparameter of type integer, that is used to control the importance of soft labels. Temperature enables student model to learn better from small differences in soft labels. Softmax helps to amplify small differences between logits, logarithmic softmax softens the gradients protecting from exploding/vanishing gradients. Hence, logsoftmax is applied to student logits. In addition to KD loss, cross entropy loss that represents classification error is used to improve the misclassification error of student model. Cross entropy loss, is defined as
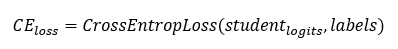
The total KD Loss is defined as — KL loss + Cross Entropy loss, the final loss is then backpropagated to fine tune the student model. Student model can be trained using an offline fine-tuned teacher model as described in the notebook. The other alternative approach is to fine tune the teacher model along with the student model.
Summary
Knowledge distillation has several advantages over RAG based implementations, especially for large language models. Some of the benefits are:
- Reducing the computational cost and memory footprint of the model, that makes it easier to deploy and run on different devices.
- Improving the generalization and robustness of the model, as the student can learn from the teacher’s implicit regularization and noise smoothing.
- Enhancing the interpretability and explainability of the model, as the student can have a simpler and more transparent structure than the teacher.
The responses from fine-tuned large models can be used in different ways to enhance the learning capabilities of student models — forward KL divergence is one such approach. This is an active area of research, you may find few alternative approaches to KD in MiniLLM (source)
